现在各种机器学习、深度学习第三方库都有非常成熟高效的神经网络实现,借助这些第三方库,短短几行代码就能实现一个神经网络。但是对于一个机器学习/深度学习的入门者来说,这些代码封装得太过彻底,往往一行代码就能实现BP算法或者梯度下降算法,这导致很多初学者即使掌握了繁复的数学推导后,依旧对神经网络的工作流程没有一个直观的认知。在我看来,自己动手实现一个神经网络,包括BP算法,梯度下降算法等,是将理论应用于实践的最佳尝试。
实验整体介绍
本次实验将在MNIST数据集上进行,MNIST是一个0-9手写数字数据集,每个样本是28*28的灰度图。官方数据集包含训练样本60000条,测试样本10000条,下面是一些手写数字样例:




本实验没有选择官网上的数据集,而是选择deeplearning.net上公布的数据集,其将数据集分成了训练集、验证集和测试集,其大小分别是50000,10000,10000,同时将样本的每个像素值归一化到[0,1]之间了。因此可以确定模型的输入是784维;输出是10维,对应每个数字的概率。显而易见,这是一个多分类问题,可以采用Softmax回归对输入特征进行分类。
Softmax回归
计算模型输出
首先从最简单的Softmax回归开始,我们不对输入向量进行任何特征提取,直接利用Softmax回归对其进行分类,如下图所示:

因此,可以写出Softmax回归的数学表达式:
y
=
s
o
f
t
m
a
x
(
x
w
)
y = softmax(xw)
y=softmax(xw)
其中, w w w是模型的权重,大小为784*10, x x x是输入,大小为m*784, y y y是输出,大小为m*10。
将Softmax函数展开,如下图所示:

其中,虚线框内就是Softmax函数的处理过程,可以看到,Softmax函数形式如下:
y
i
=
e
z
i
∑
k
e
z
k
y_i=\frac{e^{z_i}}{\sum_ke^{z_k}}
yi=∑kezkezi
因此,Softmax回归代码表示如下:
def SoftmaxRegression(x, w):
z = np.dot(x, w)
e = np.exp(z)
y = (np.transpose(e) / np.sum(e, axis=1)).T
计算模型损失
损失函数选择负对数似然函数,也即最大似然估计,因此损失函数的数学表达式是:
C
=
−
log
y
r
C=-\log y_r
C=−logyr
y r y_r yr是样本标签 r r r对应的预测概率值,以手写数字识别为例,假设某样本对应的真实标签是3,而神经网络预测样本是3的概率为 y r y_r yr,显然 y r y_r yr越接近于1,网络预测得越准,反之 y r y_r yr越接近于0,网络预测越不准,给予的惩罚也应该越大,负对数似然函数恰好满足该性质。
因此,负对数似然代价代码表示如下:
def negative_log_likehood(p_y_given_x, y):
return -np.mean(np.log(p_y_given_x)[np.arange(y.shape[0]), y])
"p_y_given_x"是模型的输出,表示样本属于每个标签的概率,"y"是样本真实标签。
接着是最小化损失,得到最优模型参数。计算损失函数的最小值采用的是梯度下降算法,其需要计算损失函数在 w w w处的梯度值。
计算 ∇ C ( w ) \nabla C(w) ∇C(w)
∂ C ∂ w = ∂ C ∂ z ∂ z ∂ w \frac{\partial C}{\partial w} = \frac{\partial C}{\partial z}\frac{\partial z}{\partial w} ∂w∂C=∂z∂C∂w∂z
其中, ∂ z ∂ w = x \frac{\partial z}{\partial w}=x ∂w∂z=x,所以要求的只有 ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C。
根据
C
=
−
log
y
r
y
r
=
e
z
r
∑
k
e
z
k
C = -\log y_r\\ y_r=\frac{e^{z_r}}{\sum_ke^{z_k}}
C=−logyryr=∑kezkezr
可以发现每一个 z i z_i zi的变化都会导致 y r y_r yr的变化,最终导致损失的变化。从公式中我们也注意到,当 i = r \bold{i=r} i=r时,影响的传播如下:
Δ z r ⟶ y r ⟶ C ↘ ∑ ↗ \begin{aligned} \Delta z_r&\quad\longrightarrow\quad y_r \longrightarrow C\\ &\searrow \textstyle\sum\nearrow \end{aligned} Δzr⟶yr⟶C↘∑↗
所以
(1)
∂
C
∂
z
r
=
∂
C
∂
y
r
∂
y
r
∂
z
r
=
−
1
y
r
(
e
z
r
∑
k
e
z
k
−
e
z
r
e
z
r
(
∑
k
e
z
k
)
2
)
=
−
1
y
r
(
y
r
−
y
r
2
)
=
y
r
−
1
\frac{\partial C}{\partial z_r}=\frac{\partial C}{\partial y_r}\frac{\partial y_r}{\partial z_r}=-\frac{1}{y_r}(\frac{e^{z_r}}{\sum_ke^{z_k}}-e^{z_r}\frac{e^{z_r}}{(\sum_ke^{z_k})^2})=-\frac{1}{y_r}(y_r-y_r^2)=y_r-1 \tag 1
∂zr∂C=∂yr∂C∂zr∂yr=−yr1(∑kezkezr−ezr(∑kezk)2ezr)=−yr1(yr−yr2)=yr−1(1)
同理,当
i
=
/
 
r
\bold{i {=}\mathllap{/\,} r}
i=/r时,影响传播图如下:
Δ
z
i
⟶
∑
⟶
y
r
⟶
C
\Delta z_i \longrightarrow \textstyle\sum \longrightarrow y_r \longrightarrow C
Δzi⟶∑⟶yr⟶C
所以
(2)
∂
C
∂
z
i
=
∂
C
∂
y
r
∂
y
r
∂
z
i
=
−
1
y
r
(
−
e
z
r
e
z
i
(
∑
k
e
z
k
)
2
)
=
−
1
y
r
(
−
y
r
y
r
)
=
y
i
−
0
\frac{\partial C}{\partial z_i}=\frac{\partial C}{\partial y_r}\frac{\partial y_r}{\partial z_i}=-\frac{1}{y_r}(-e^{z_r}\frac{e^{z_i}}{(\sum_ke^{z_k})^2})=-\frac{1}{y_r}(-y_ry_r)=y_i-0 \tag 2
∂zi∂C=∂yr∂C∂zi∂yr=−yr1(−ezr(∑kezk)2ezi)=−yr1(−yryr)=yi−0(2)
将(1)和(2)统一起来,写成向量形式有
∂
C
∂
z
=
y
−
y
^
\frac{\partial C}{\partial z}=y - \hat{y}
∂z∂C=y−y^
其中, y ^ \hat{y} y^是样本真实标签对应的one-hot向量表示,可以由下面代码转换得到:
def getTruthmatrix(y):
matrix = np.zeros((len(y), 10))
for i in np.arange(len(y)):
matrix[i, y[i]] = 1
return matrix
最终,
∇
C
(
w
)
\nabla C(w)
∇C(w)的表达式如下:
∂
C
∂
w
=
∂
C
∂
z
∂
z
∂
w
=
x
T
(
y
−
y
^
)
\frac{\partial C}{\partial w} = \frac{\partial C}{\partial z}\frac{\partial z}{\partial w}=x^T(y-\hat{y})
∂w∂C=∂z∂C∂w∂z=xT(y−y^)
表示成代码如下:
def grad(x, y, y_truth_matrix):
grad_w = np.dot(np.transpose(x), y - y_truth_matrix) / y_truth_matrix.shape[0]
return grad_w
更新梯度
有了在每个
w
w
w处的梯度值,就可以调用梯度下降算法迭代更新
w
w
w了,根据梯度下降算法,
w
n
+
1
=
w
n
−
α
∇
C
(
w
n
)
w^{n+1} = w^n-\alpha \nabla C(w^n)
wn+1=wn−α∇C(wn)
有梯度下降的代码如下:
def gradient_descent(x, y, w, alpha):
y_truth_matrix = getTruthmatrix(y)
# 正向传播得到模型预测值
probabilities = SoftmaxRegression(x, w)
# 损失
cost = negative_log_likehood(probabilities, y) # 权重w更新前的误差
# 计算梯度
grad_w = grad(x, y, y_truth_matrix)
# 更新参数
new_w = w - alpha * grad_w
return (new_w, cost)
以上就是Softmax回归的主要流程,重复上述梯度更新步骤,直至前后两次更新的损失不再下降(小于指定阈值)或者达到迭代次数。关于梯度下降的更多原理可以参考这篇博客。
神经网络
我们都知道,神经网络的隐含层可以看作是特征提取的过程,然后根据指定任务接一个输出层,所以针对我们的手写数字识别问题,输出层将是Softmax层,形式如下图所示:

首先,对神经网络中的用到的符号进行指定:
z
l
:
z^l:
zl:第
l
l
l层神经元的输入;
a
l
:
a^l:
al:第
l
l
l层神经元的输出;
w
i
j
l
:
w_{ij}^l:
wijl:连接
l
−
1
l-1
l−1层第
i
i
i个神经元与
l
l
l层第
j
j
j个神经元的权重;
L
L
L:输出层
前向传播
输入 x x x经过每一层连接权重和神经元激活函数,逐层传播,其代码形式如下:
def forward_porpagation(x, W):
activations = [x] # 用于存储每一层的输出
zs = [x] # 用于存储每一层的输入
a = x
# 隐藏层
for i in range(len(W) - 1):
z = np.dot(a, W[i])
zs.append(z)
a = sigmoid(z)
activations.append(a)
# 输出层
z = np.dot(a, W[-1])
e = np.exp(z)
zs.append(z)
p = (np.transpose(e) / np.sum(e, axis=1)).T
activations.append(p)
return (activations, zs)
注意,此时 W W W是一个列表,每个元素表示每一层连接权重,"zs"和"activations"分别用来保存每一层的输入和输出。
损失函数同样是负对数似然函数,同样需要计算 ∂ C ∂ w \frac{\partial C}{\partial w} ∂w∂C,但神经网络包含参数数目巨大,求导过程复杂,分开求每一层 w l w^l wl将非常耗时,同时,我们发现在求解前面层权重的导数的过程中会包含求解其后面层权重的导数,此时就需要采用BP算法。
BP算法推导
对于神经网络中任意一个权重
w
i
j
l
w_{ij}^l
wijl,其对于损失的影响传播过程如下:
Δ
w
i
j
l
⟶
z
i
l
⟶
⋯
⟶
C
\Delta w_{ij}^l\longrightarrow z_i^l\longrightarrow \cdots\longrightarrow C
Δwijl⟶zil⟶⋯⟶C
所以
∂
C
∂
w
i
j
l
=
∂
C
∂
z
j
l
∂
z
j
l
∂
w
i
j
l
\frac{\partial C}{\partial w_{ij}^l}=\frac{\partial C}{\partial z_j^l}\frac{\partial z_j^l}{\partial w_{ij}^l}
∂wijl∂C=∂zjl∂C∂wijl∂zjl
其中
∂
z
j
l
∂
w
i
j
l
=
a
i
l
−
1
\frac{\partial z_j^l}{\partial w_{ij}^l}=a_i^{l-1}
∂wijl∂zjl=ail−1,剩下关键要求的就是
∂
C
∂
z
j
l
\frac{\partial C}{\partial z_j^l}
∂zjl∂C,令其等于
δ
j
l
\delta_{j}^l
δjl,我们知道
z
j
l
z_j^l
zjl是第
l
l
l层第
j
j
j个神经元的输入,经过一个激活函数得到该神经元的输出
a
j
l
a_j^l
ajl,通常除去输出层会根据任务的不同而选择不同的激活函数外(如二分类问题选择logistics函数,多分类问题选择softmax函数),其他层神经元的激活函数往往相同。因此,我们在计算
∂
C
∂
z
j
l
\frac{\partial C}{\partial z_j^l}
∂zjl∂C时需要分为输出层与非输出层。
1、当
l
l
l是输出层时,为了区别开来,我们将
l
l
l写成
L
L
L,其影响传播如下:
Δ
z
j
L
⟶
a
j
L
=
y
j
L
⟶
C
\Delta z_j^L\longrightarrow a_j^L=y_j^L\longrightarrow C
ΔzjL⟶ajL=yjL⟶C
所以
∂
C
∂
z
j
L
=
∂
C
∂
y
j
L
∂
y
j
L
∂
z
j
L
=
∇
C
(
y
L
)
∗
σ
′
(
z
j
L
)
\frac{\partial C}{\partial z_j^L}=\frac{\partial C}{\partial y_j^L}\frac{\partial y_j^L}{\partial z_j^L}=\nabla C(y^L)*\sigma'(z_j^L)
∂zjL∂C=∂yjL∂C∂zjL∂yjL=∇C(yL)∗σ′(zjL)
2、当 l l l非输出层时,其影响传播如下:
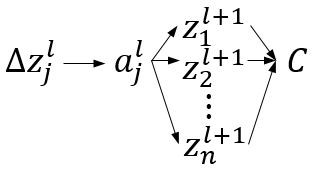
所以
∂
C
∂
z
j
l
=
∑
k
∂
C
∂
z
k
l
+
1
∂
z
k
l
+
1
∂
a
j
l
∂
a
j
l
∂
z
j
l
=
∑
k
δ
k
l
+
1
w
j
k
l
+
1
σ
′
(
z
j
l
)
\frac{\partial C}{\partial z_j^l}=\sum_k\frac{\partial C}{\partial z_k^{l+1}}\frac{\partial z_k^{l+1}}{\partial a_j^l}\frac{\partial a_j^l}{\partial z_j^l}=\sum_k \delta_k^{l+1}w_{jk}^{l+1}\sigma'(z_j^l)
∂zjl∂C=k∑∂zkl+1∂C∂ajl∂zkl+1∂zjl∂ajl=k∑δkl+1wjkl+1σ′(zjl)
关于BP算法的更多推导可以参考我之前的博客《计算图(Computational Graph)的角度理解反向传播算法(Backpropagation)》和《反向传播(BP)算法》,里面有更加详细的推导。
针对我们手写数字识别问题,将其写成矩阵形式如下:
δ
L
=
y
−
y
^
δ
l
=
δ
l
+
1
(
w
l
+
1
)
T
∗
σ
′
(
z
l
)
\begin{aligned} \delta^L&=y-\hat{y}\\ \delta^l&=\delta^{l+1}(w^{l+1})^T*\sigma'(z^l) \end{aligned}
δLδl=y−y^=δl+1(wl+1)T∗σ′(zl)
反向传播算法的代码形式如下:
def backprop(activations, zs, w, y):
grad_w = [np.zeros(weight.shape) for weight in w]
# 反向传播
delta = activations[-1] - y # 最后一层, m*10
grad_w[-1] = np.dot(np.transpose(activations[-2]), delta)
for l in range(2, len(w) + 1):
delta = np.dot(delta, w[-l+1].transpose()) * sigmoid_derivative(zs[-l]) # 其它层
grad_w[-l] = np.dot(np.transpose(activations[-l-1]), delta) / y.shape[0]
return grad_w
然后采用梯度下降算法对权重进行更新。
模型构建与优选
通常,我们在训练集上训练模型,更新模型参数,在验证集上对模型性能进行验证,当模型在验证集上的性能达到要求时,得到的模型就是最优模型,然后在测试集上测试模型。
def build_model(datasets, w_initial, alpha, n_epochs, epsilon, batch_size):
W = w_initial
# 训练集,验证集,测试集
train_set_x, train_set_y = datasets[0]
valid_set_x, valid_set_y = datasets[1]
test_set_x, test_set_y = datasets[2]
# 将数据集分成较小的batch
n_train_batches = train_set_x.shape[0] // batch_size # 训练集划分成batch数目
# 模型训练
best_valid_cost = 0
validation_frequency = 100 # 梯度下降迭代validation_frequency次,在验证集上验证一次模型性能
epoch = 0
done_looping = False
while (epoch < n_epochs) and (not done_looping):
epoch += 1
for batch_index in range(n_train_batches):
x = train_set_x[batch_index * batch_size: (batch_index + 1) * batch_size] # 每次训练的x
y = train_set_y[batch_index * batch_size: (batch_index + 1) * batch_size] # 对应的y
# 训练模型
W, cost_train = gradient_descent(x, y, W, alpha, L1_reg, L2_reg)
# 验证模型
cost_valid, error_num_valid = valid_model(valid_set_x, valid_set_y, W)
this_validation_loss = error_num_valid / valid_set_x.shape[0] # 错误率
num_iter = (epoch - 1) * n_train_batches + batch_index
if num_iter % validation_frequency == 0:
# 跟踪验证集上性能变化
print("梯度下降迭代%d次后,验证集上误差为:%f,准确率为:%f%%" % (num_iter, cost_valid, (1 - this_validation_loss) * 100))
# 判断是否early stopping
if abs(cost_valid - best_valid_cost) < epsilon:
done_looping = True
print("验证集上误差不再下降,模型训练结束")
break
else:
best_valid_cost = cost_valid
if not done_looping:
print("达到最大epoch次数,模型训练结束")
# 模型测试
test_precision = test_model(test_set_x, test_set_y, W)
print("测试集上模型准确率为:%f%%" % (test_precision * 100))
总结
以上实现了一个最简单的Softmax回归和神经网络,上面只贴出了主要步骤的代码实现,完整的代码可以在下面这个链接下载,代码在linux环境下实现,如有问题,欢迎多多交流!
参考文献
DeepLearningTutorials
Softmax-Regression
神经网络中 BP 算法的原理与 Python 实现源码解析
Python Image.fromarray() doesn’t accept my ndarray input which is built from a list




